Dienstag30. Juni
Agentic AI dominiert heute auf zwei Achsen: Skalierung (Memora, ENPIRE, Gartner-Outlook) und Sicherheit (Claude-Code-Malware, Meta-Datenprovenienz). Daneben setzen konkrete Tool-Releases und Markt-Infrastruktur-Moves den Builder-Takt.


Die Sicherheitsdimension agentic KI rückt heute besonders scharf in den Fokus. Sicherheitsforscher von 0DIN, Mozillas GenAI-Bug-Bounty-Plattform, haben einen neuen Angriffsvektor dokumentiert: Ein normales GitHub-Repository kann über einen Setup-Skript, der zur Laufzeit einen Befehl aus einem DNS-Eintrag zieht und ausführt, Claude Code zur Ausführung einer Reverse Shell veranlassen — ohne dass der Schadcode je im Repository selbst auftaucht. Statische Scanner, Code-Reviews und der Agent selbst bleiben blind. Empfehlung der Forscher: Agenten sollten Setup-Skripte vor der Ausführung anzeigen, und Entwickler sollten Drittanbieter-Repos grundsätzlich als nicht vertrauenswürdigen Code behandeln. Parallel dazu offenbart Metas Entscheidung, den Einsatz von Claude Code und Codex intern einzuschränken, eine zweite Sicherheitsebene: Nicht der Angriff von außen, sondern unkontrollierte Datenprovenienz im eigenen Haus. Laut internen Dokumenten, die The Information vorliegen, fürchtet Meta die unbeabsichtigte Destillation von Konkurrenzmodellen in die eigenen Trainingsdaten — ein Problem, das auch Anthropic (gegen Alibaba) und xAI (mit OpenAI-Modellen) bereits betroffen hat. Meta baut derzeit seinen eigenen Coding-Assistenten MetaCode auf und will die Abhängigkeit von externen Tools reduzieren, auch wegen steigender Kosten; interne Memos sprechen von milliardenschweren Ausgaben für KI-Tools allein in diesem Jahr.

Dass KI-Coding-Tools Geschwindigkeit erzeugen, aber keine durchgängige Lieferbeschleunigung, bestätigt unterdessen ein GitLab-Report, der diesen Widerspruch als „AI Paradox" benennt: 78 % der Entwickler berichten von schnellerer Code-Produktion, 73 % von verbesserter Qualität — doch 79 % sagen, die Gesamtlieferung hat sich nicht im gleichen Tempo beschleunigt. Der Engpass hat sich laut 85 % der Befragten von der Codeerstellung ins Review und Testing verlagert. Dazu kommen Governance-Lücken: Nur 34 % der Unternehmen, die in den vergangenen zwölf Monaten einen Produktionsvorfall hatten, konnten tatsächlich innerhalb von 24 Stunden bestimmen, ob AI-generierter Code dazu beigetragen hatte — obwohl 87 % der Befragten glaubten, dazu in der Lage zu sein. Die Frage, woher Code stammt, wer dafür verantwortlich ist und was er tun soll, ist für die meisten Organisationen heute nicht zuverlässig beantwortbar. Einen konkreten Praxisblick auf die Stärken und Grenzen von Coding-Agenten liefert der htmx-Autor Carson Gross in seiner Fallstudie mit Claude beim Parser-Debugging: Der Agent half, die Ursache einer Regression in Minuten zu identifizieren — beim Fix jedoch produzierte er zunächst zu enge oder überkomplexe Lösungen. Gross beschreibt das als „Sorcerer's Apprentice Problem": Wer den eigenen Code nicht tief genug kennt, akzeptiert einen Hack statt der saubereren Lösung.

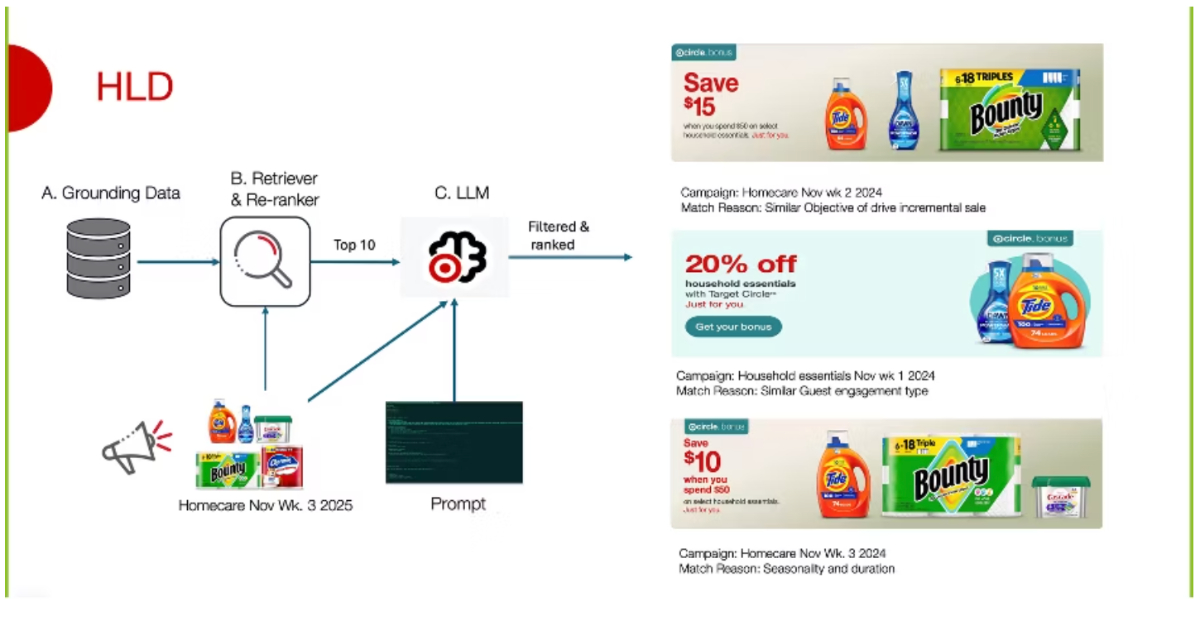
Auf der Architekturebene liefern zwei Veröffentlichungen heute die technische Gegenthese zur reinen Skalierungsdebatte. Microsofts Memora-System, veröffentlicht auf der ICML 2026, entkoppelt Speicherinhalt und Retrieval-Schicht für langlebige Agenten-Deployments: Statt den gesamten Gesprächsverlauf in den Kontext zu laden, nutzt Memora leichtgewichtige Strukturabstraktionen — und erreicht damit laut Microsoft bis zu 98 % weniger Kontext-Tokens bei gleichzeitig neuen State-of-the-Art-Werten auf den Benchmarks LoCoMo und LongMemEval. Komplementär dazu setzt Targets neues LLM-basiertes Retrieval-System für Marketing-Prognosen auf semantisches Matching statt regelbasierter Logik: Historische Kampagnendaten werden als Embeddings indexiert, neue Kampagnen gegen diesen Index verglichen und per LLM-Ranking verfeinert. Beim Top-3-Matching erreichte das System 100 % Coverage über alle evaluierten Kampagnen — verglichen mit dem vorherigen regelbasierten Ansatz, der bei neueren Kampagnenformaten zunehmend versagte.

Zwei Marktmoves setzen den infrastrukturellen Rahmen. Gartner bezeichnet 2026 als „Inflection Year" für Enterprise-AI: Laut einer MIT-Technology-Review-Studie mit 300 globalen Technologieexperten im Auftrag von Microsoft ist das Vertrauen in Agenten für messbare, strukturierte Tasks — Datenqualitäts-Monitoring, Report-Generierung, Anomalieerkennung — bereits hoch; es fällt vor allem dort, wo Agenten Business-Kontext eigenständig generieren müssen, der noch nicht in strukturierter Form vorliegt. Auf staatlicher Ebene verpflichtet sich Südkorea zu einem Billionen-Dollar-Programm aus Chip-Fabs, KI-Rechenzentren und Humanoid-Robotik: Samsung und SK Hynix binden 585 Milliarden Dollar für neue DRAM-Produktionsanlagen, SK Group, GS Group und Naver weitere 357 Milliarden für großflächige AI-Datenzentren. Hyundai und Boston Dynamics planen, bis 2028 jährlich 30.000 Atlas-Roboter zu produzieren. Entlastung bei Speicherchippreisen bleibt jedoch unsicher — SK-Hynix-Chef Chey Tae-won verwies darauf, dass der Aufbau eines Chip-Clusters in Yongjin neun Jahre beansprucht hatte.

Für Builder und Teams, die heute entscheiden müssen, welche Modellklasse für welchen Workload geeignet ist, liefert ein praxisorientierter Entscheidungsrahmen aus *Towards Data Science* eine belastbare Grundlage: NVIDIA Research schätzt, dass 40 bis 70 % der Enterprise-AI-Tasks auf Modellen mit weniger als 10 Milliarden Parametern lösbar sind. Ein Tiered-Routing-Ansatz — 70 % lokale SLMs, 20 % Mid-Tier, 10 % Frontier — senkt Kosten und Datenschutzrisiken, was besonders mit Blick auf den EU AI Act (Enforcement ab 2. August 2026) und HIPAA-kritische Workloads relevant wird. Auf der Tool-Ebene demonstriert Qwen3-TTS.cpp, wie weit Community-Infrastruktur heute reicht: Die GGML-basierte TTS-Engine läuft 15-mal schneller als die Python-Referenzimplementierung, unterstützt Voice Cloning, Speaker-Embedding-Mix und Streaming — direkt auf CPU und CUDA, ohne Python-Stack, mit vorkompilierten Windows-Releases. Der Builder-Takt, den diese Releases setzen, läuft der Enterprise-Governance-Debatte einstweilen deutlich voraus.
Frag das Briefing
Pro



- Mo., 29. JuniChinesische Modelle greifen US-Frontier an: GLM-5.2 schlägt Claude Code bei Security-Benchmarks, Coinbase halbiert KI-Kosten mit China-Routing. Dazu: Multi-LoRA-Serving auf A100, Agentic-Workflows unter Varianz-Kontrolle und ein wachsendes Open-Source-Ökosystem.10
- So., 28. JuniDelegation und Infrastrukturkosten dominieren heute: Anthropics eigene Daten zeigen explodierende Automatisierungserwartungen, während Big Tech RAM-Engpässe auf Endkunden abwälzt. Dazu: konkrete Builder-Tools von lokalem Image-Inference bis Coding-Agents.10
- Sa., 27. JuniStaatliche Zugangsbeschränkungen für GPT-5.6 und Anthropic-Modelle dominieren heute – AI-Builder müssen regulatorische Abhängigkeiten neu einkalkulieren. Daneben setzen neue Tools von Vercel und Dapr sowie ein härteres Coding-Benchmark konkrete Maßstäbe für Produktions-Infrastruktur.10
- Fr., 26. JuniAgentic Tooling dominiert: Von Vercel AI SDK 7 bis Cloudflare Zero-Trust-Skills zieht sich ein roter Faden durch den heutigen Tag — Agents werden produktionsreif. Dazu: Hardware-Sprünge (IBM, Unconventional AI) und Regulierungs-Signale, die Enterprise-Roadmaps neu sortieren.10