NVIDIA stellt Nemotron 3 Nano Omni vor: Multimodales Reasoning-Modell für Agenten
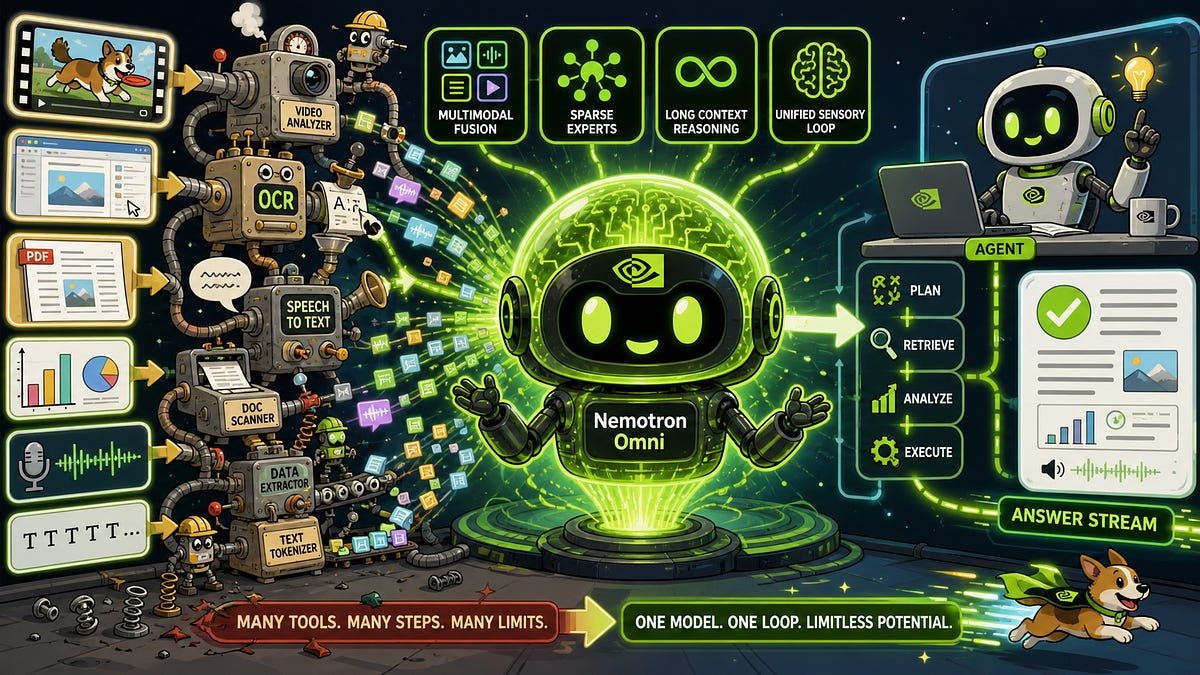
NVIDIA kündigte am 28. April 2026 Nemotron 3 Nano Omni an, ein neues Modell der Nemotron-Familie, das Video, Audio, Bilder und Text in einer einzigen Perception-und-Reasoning-Pipeline verarbeitet. Das Modell adressiert ein zentrales Problem moderner Agenten-Stacks: Die fragmentierte Architektur, bei der Audio an ASR-Modelle, Screenshots an VLMs, PDFs an OCR-Systeme und Video-Frames an separate Modelle gehen, führt zu Informationsverlust an jeder Schnittstelle. Der Sprach-Parser erfasst möglicherweise nicht, was gleichzeitig auf dem Bildschirm passiert; das Vision-Modell sieht den Chart ohne den zugehörigen Voice-Over. Nemotron Omni konsolidiert diese Architektur in ein Modell, das als skalierbar und effizient für Agentic-Workflows wie Computer-Nutzung, Dokumentanalyse und längerfristige Audio-Video-Verarbeitung ausgelegt ist. Die Lösung wird als Open-Modell positioniert.
- Angekündigt am 28. April 2026 als Teil der Nemotron-Familie
- Konsolidiert Video-, Audio-, Bild- und Text-Verarbeitung in einem Modell
- Zielgruppe: Computer-Use-Agenten, Dokumentintelligenz und mehrstündige Audio-Video-Verarbeitung
- Adressiert Problem der 'lossy compression' an Modellgrenzen in bestehenden Stacks
- Positioniert als Open-Modell für Agentic Workflows
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
NVIDIA stellt Nemotron 3 Nano Omni vor: Multimodales Reasoning-Modell für Agenten
NVIDIA kündigte am 28. April 2026 Nemotron 3 Nano Omni an, ein neues Modell der Nemotron-Familie, das Video, Audio, Bilder und Text in einer einzigen Perception-und-Reasoning-Pipeline verarbeitet. Das Modell adressiert ein zentrales Problem moderner Agenten-Stacks: Die fragmentierte Architektur, bei der Audio an ASR-Modelle, Screenshots an VLMs, PDFs an OCR-Systeme und Video-Frames an separate Modelle gehen, führt zu Informationsverlust an jeder Schnittstelle. Der Sprach-Parser erfasst möglicherweise nicht, was gleichzeitig auf dem Bildschirm passiert; das Vision-Modell sieht den Chart ohne den zugehörigen Voice-Over. Nemotron Omni konsolidiert diese Architektur in ein Modell, das als skalierbar und effizient für Agentic-Workflows wie Computer-Nutzung, Dokumentanalyse und längerfristige Audio-Video-Verarbeitung ausgelegt ist. Die Lösung wird als Open-Modell positioniert.
- Angekündigt am 28. April 2026 als Teil der Nemotron-Familie
- Konsolidiert Video-, Audio-, Bild- und Text-Verarbeitung in einem Modell
- Zielgruppe: Computer-Use-Agenten, Dokumentintelligenz und mehrstündige Audio-Video-Verarbeitung
- Adressiert Problem der 'lossy compression' an Modellgrenzen in bestehenden Stacks
- Positioniert als Open-Modell für Agentic Workflows
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.