Tutorial: Retrieve-and-Rerank-Pipeline mit ZeroEntropy Zerank-2 Reranker
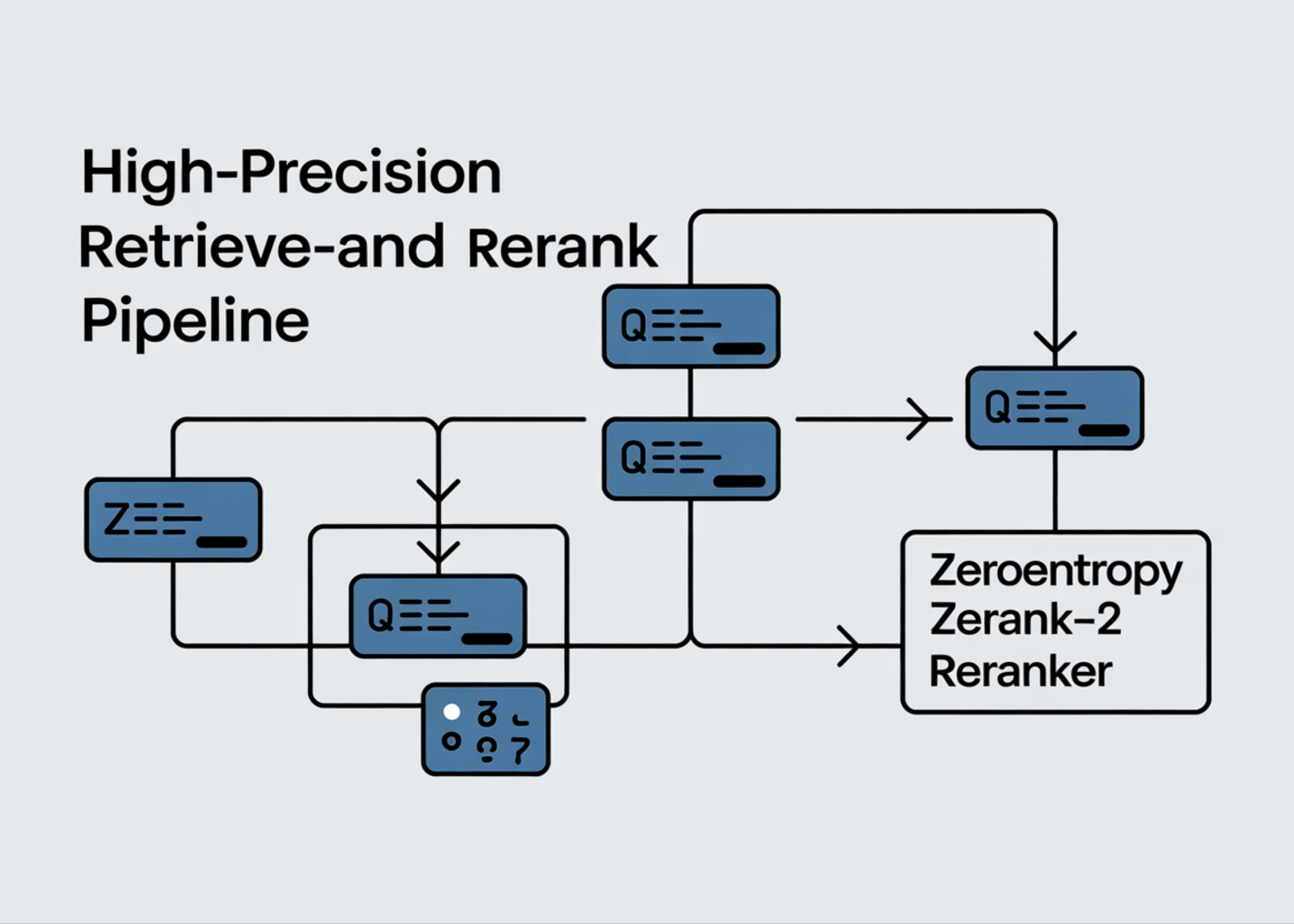
Das Tutorial auf MarkTechPost führt Schritt für Schritt durch den Aufbau einer zweistufigen Retrieve-and-Rerank-Pipeline mithilfe des Modells zeroentropy/zerank-2-reranker. Das Modell basiert auf einer 4-Milliarden-Parameter-Architektur, die auf Qwen3 als Backbone aufbaut und als Cross-Encoder eingesetzt wird. Im Gegensatz zu Bi-Encodern bewertet ein Cross-Encoder Query und Dokument gemeinsam, was in der Regel zu höherer Präzision führt, aber mehr Rechenaufwand pro Paar erfordert. Das Tutorial erklärt zunächst die Laufzeitumgebung, das Laden des Modells und das paarweise Scoring. Anschließend wird gezeigt, wie ein schneller Bi-Encoder als erste Stufe eine Kandidatenmenge abruft und Zerank-2 in der zweiten Stufe das finale Ranking übernimmt. Dieser hybride Ansatz kombiniert Geschwindigkeit und Präzision und ist ein gängiges Muster in modernen RAG-Systemen (Retrieval-Augmented Generation).
- Modell-ID: zeroentropy/zerank-2-reranker, basierend auf Qwen3 mit 4B Parametern
- Architektur: Cross-Encoder — bewertet Query-Dokument-Paare gemeinsam statt separat
- Zweistufiger Ansatz: Bi-Encoder für schnellen Kandidaten-Abruf, Zerank-2 für präzises Reranking
- Tutorial deckt Setup, Modell-Loading und praktische Pipeline-Integration ab
- Veröffentlicht von MarkTechPost als vollständiges How-to mit Code-Walkthrough
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
Tutorial: Retrieve-and-Rerank-Pipeline mit ZeroEntropy Zerank-2 Reranker
Das Tutorial auf MarkTechPost führt Schritt für Schritt durch den Aufbau einer zweistufigen Retrieve-and-Rerank-Pipeline mithilfe des Modells zeroentropy/zerank-2-reranker. Das Modell basiert auf einer 4-Milliarden-Parameter-Architektur, die auf Qwen3 als Backbone aufbaut und als Cross-Encoder eingesetzt wird. Im Gegensatz zu Bi-Encodern bewertet ein Cross-Encoder Query und Dokument gemeinsam, was in der Regel zu höherer Präzision führt, aber mehr Rechenaufwand pro Paar erfordert. Das Tutorial erklärt zunächst die Laufzeitumgebung, das Laden des Modells und das paarweise Scoring. Anschließend wird gezeigt, wie ein schneller Bi-Encoder als erste Stufe eine Kandidatenmenge abruft und Zerank-2 in der zweiten Stufe das finale Ranking übernimmt. Dieser hybride Ansatz kombiniert Geschwindigkeit und Präzision und ist ein gängiges Muster in modernen RAG-Systemen (Retrieval-Augmented Generation).
- Modell-ID: zeroentropy/zerank-2-reranker, basierend auf Qwen3 mit 4B Parametern
- Architektur: Cross-Encoder — bewertet Query-Dokument-Paare gemeinsam statt separat
- Zweistufiger Ansatz: Bi-Encoder für schnellen Kandidaten-Abruf, Zerank-2 für präzises Reranking
- Tutorial deckt Setup, Modell-Loading und praktische Pipeline-Integration ab
- Veröffentlicht von MarkTechPost als vollständiges How-to mit Code-Walkthrough
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.