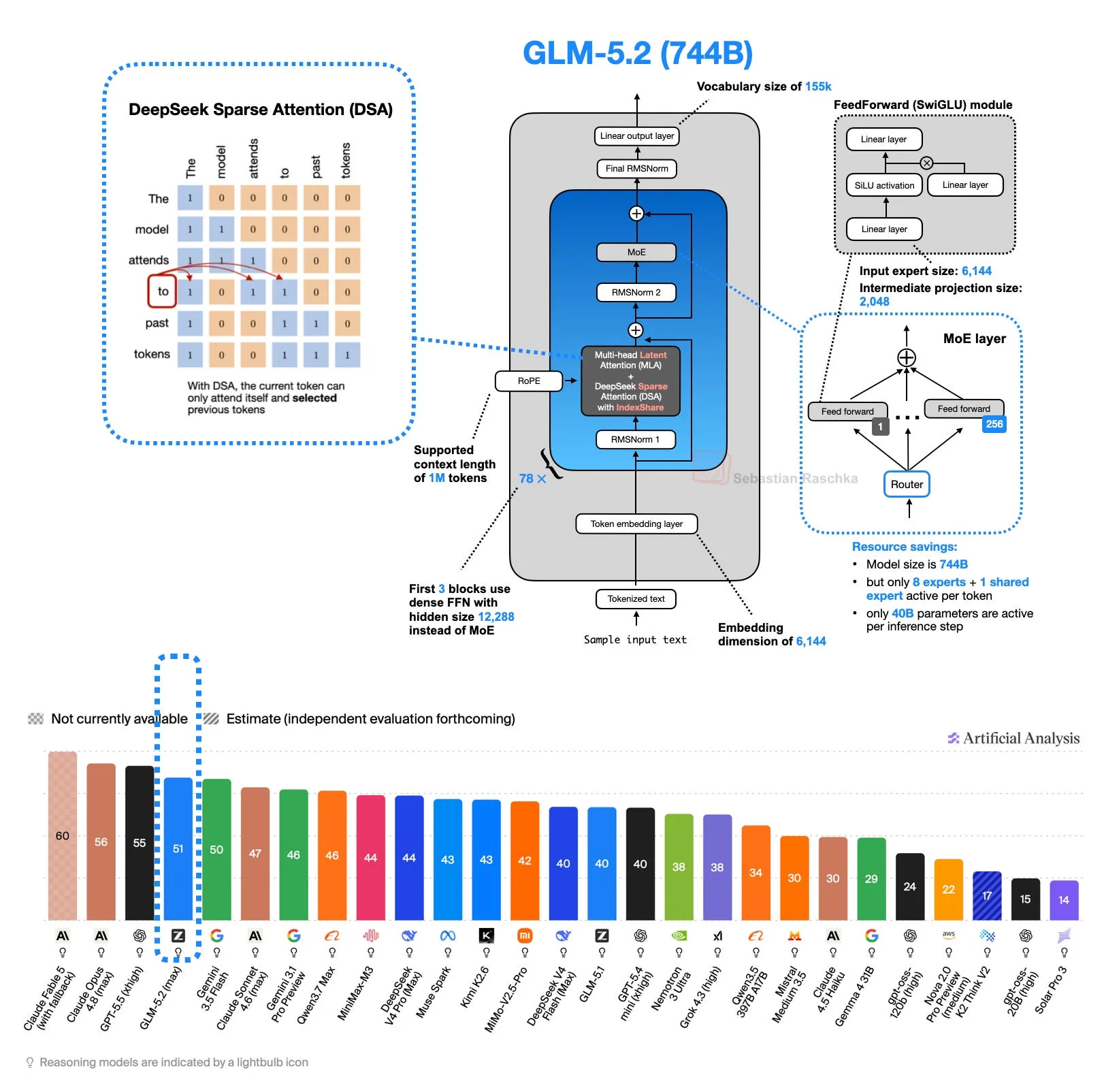
GLM-5.2 von Z.ai: IndexShare macht 1M-Token-Inferenz effizienter
ToolsDeepSeek
CompaniesDeepSeek
Warum es zählt
IndexShare reduziert den Rechenaufwand bei Sparse Attention für sehr lange Kontexte, indem Token-Indizes layerübergreifend wiederverwendet werden. Für Entwickler, die 1M-Token-Inferenz betreiben, senkt das direkt die Inferenzkosten ohne die adaptive Aufmerksamkeit grundlegend zu verändern.
— Lumeric Redaktion
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
GLM-5.2 von Z.ai: IndexShare macht 1M-Token-Inferenz effizienter
ToolsDeepSeek
CompaniesDeepSeek
Warum es zählt
IndexShare reduziert den Rechenaufwand bei Sparse Attention für sehr lange Kontexte, indem Token-Indizes layerübergreifend wiederverwendet werden. Für Entwickler, die 1M-Token-Inferenz betreiben, senkt das direkt die Inferenzkosten ohne die adaptive Aufmerksamkeit grundlegend zu verändern.
— Lumeric Redaktion
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.