Lokale Open-Weight LLMs in Coding-Harnesses: 30B MoE als Sweet Spot
Warum es zählt
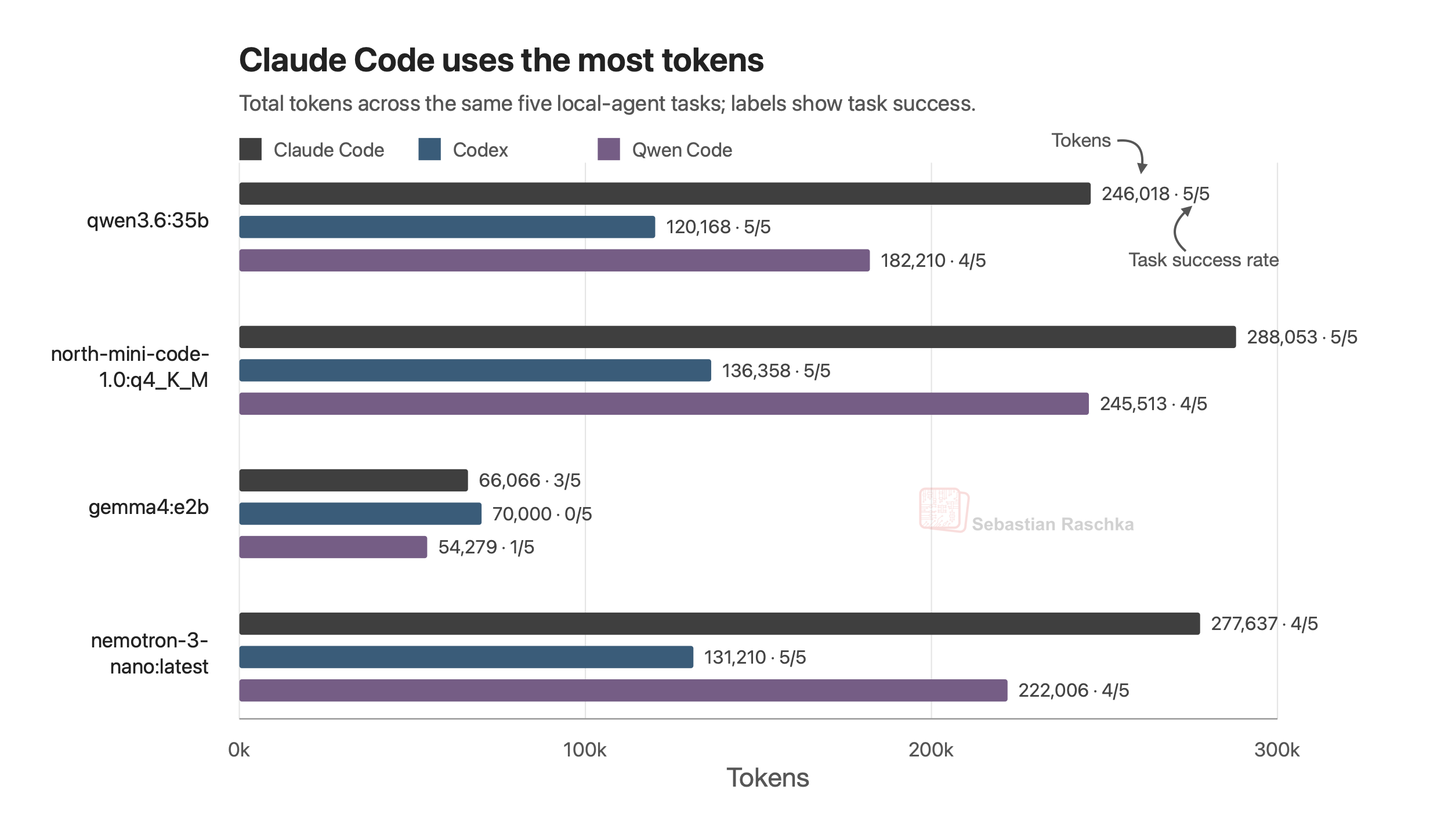
Claude Code verbraucht rund doppelt so viele Tokens wie Codex bei gleichen Aufgaben – die Harness-Wahl beeinflusst also Kosten und Effizienz erheblich. 30B-MoE-Modelle sind für lokales Coding-Agentensetup alltagstauglich, kleinere Modelle wie Gemma 4 E2B scheitern an denselben Aufgaben.
— Lumeric Redaktion
~40 tok/s
auf Mac/DGX Spark mit 30B-MoE-Modellen
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
Lokale Open-Weight LLMs in Coding-Harnesses: 30B MoE als Sweet Spot
Warum es zählt
Claude Code verbraucht rund doppelt so viele Tokens wie Codex bei gleichen Aufgaben – die Harness-Wahl beeinflusst also Kosten und Effizienz erheblich. 30B-MoE-Modelle sind für lokales Coding-Agentensetup alltagstauglich, kleinere Modelle wie Gemma 4 E2B scheitern an denselben Aufgaben.
— Lumeric Redaktion
~40 tok/s
auf Mac/DGX Spark mit 30B-MoE-Modellen
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.