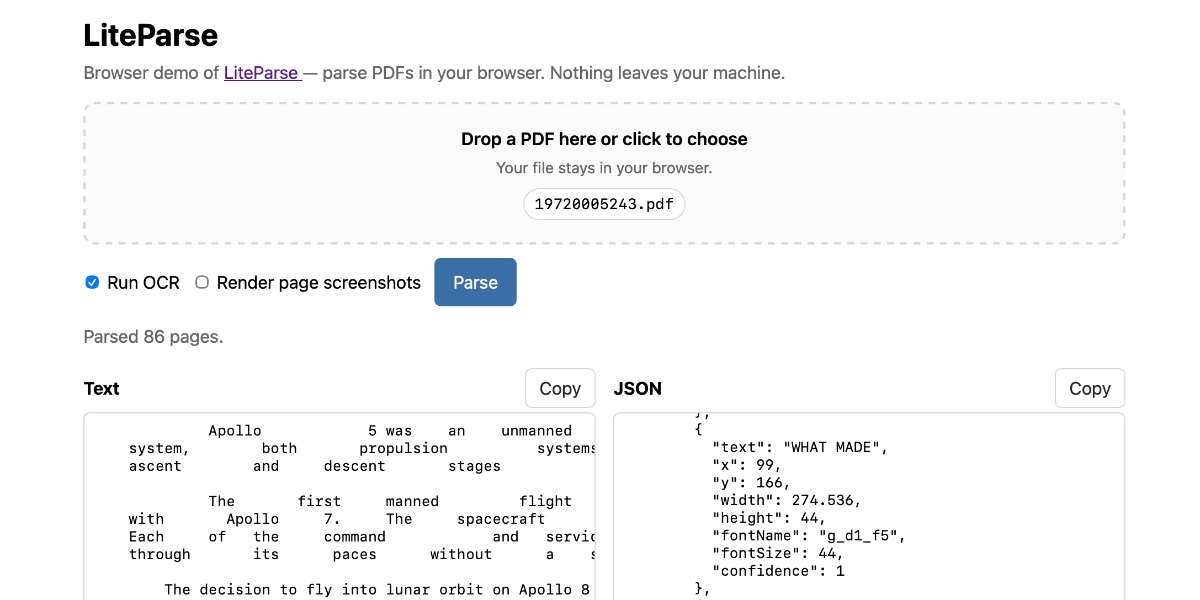
Simon Willison portiert LiteParse von LlamaIndex als Browser-Tool für PDF-Extraktion
ToolsLlamaIndex
Warum es zählt
Entwickler können PDFs nun clientseitig ohne Backend oder KI-Modelle parsen – inklusive Spalten-Erkennung und OCR-Fallback. Nützlich für RAG-Pipelines mit Bounding-Box-Zitaten direkt im Browser.
— Lumeric Redaktion
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
- MEINUNGreddit.com2w
On-Prem Dokumentenparsing für Uni: Docling, Liteparse, MinerU oder Unstructured?
- MEINUNGtowardsdatascience.com3w
EasyOCR vs. Docling: Strukturlücke beim Parsen gescannter PDFs für RAG
- MEINUNGtowardsdatascience.com3w
PDF-Bilder selektiv für RAG durchsuchbar machen ohne alle zu analysieren
Simon Willison portiert LiteParse von LlamaIndex als Browser-Tool für PDF-Extraktion
ToolsLlamaIndex
Warum es zählt
Entwickler können PDFs nun clientseitig ohne Backend oder KI-Modelle parsen – inklusive Spalten-Erkennung und OCR-Fallback. Nützlich für RAG-Pipelines mit Bounding-Box-Zitaten direkt im Browser.
— Lumeric Redaktion
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
- MEINUNGreddit.com2w
On-Prem Dokumentenparsing für Uni: Docling, Liteparse, MinerU oder Unstructured?
- MEINUNGtowardsdatascience.com3w
EasyOCR vs. Docling: Strukturlücke beim Parsen gescannter PDFs für RAG
- MEINUNGtowardsdatascience.com3w
PDF-Bilder selektiv für RAG durchsuchbar machen ohne alle zu analysieren