FrontierCode: Neues Benchmark misst ob Code wirklich merge-würdig ist
Warum es zählt
SWE-Bench-Scores täuschen über den echten Reifegrad von Coding-Agents hinweg. FrontierCode zeigt, dass mergefähiger Code ein deutlich schwiereres Ziel ist – relevant für Teams, die Agents produktiv in Codebases einsetzen wollen.
— Lumeric Redaktion
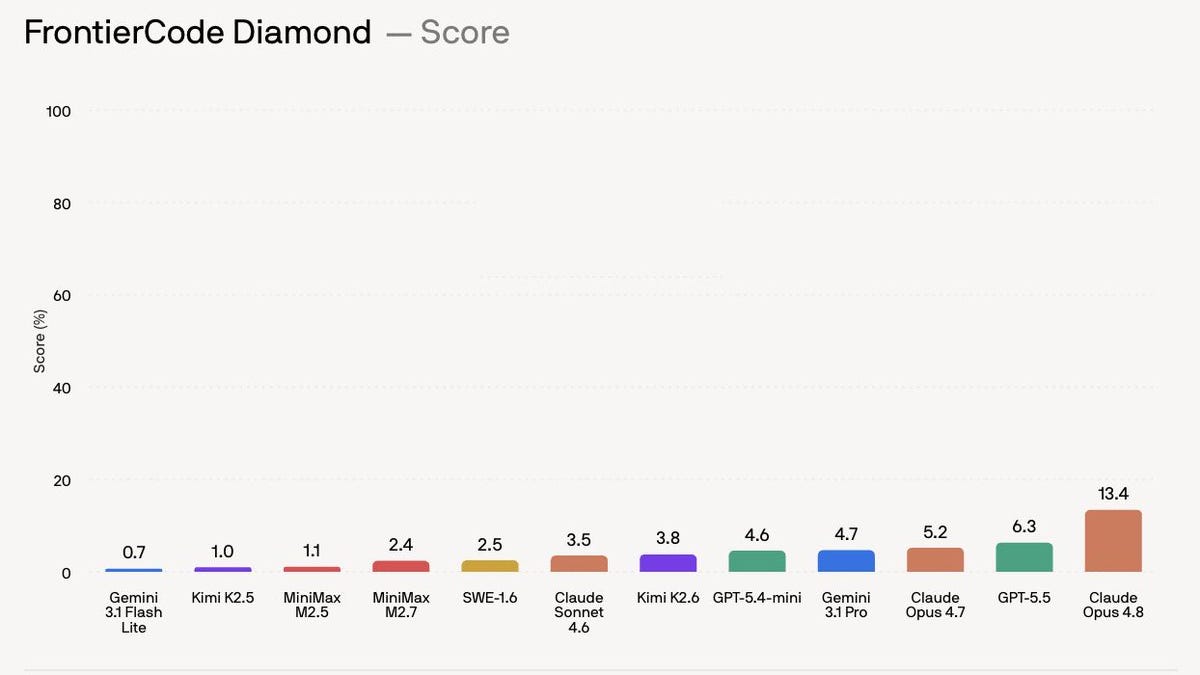
FrontierCode (hardest subset) · Spitzenwert
13%
Opus 4.8
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
- FORSCHUNGarxiv.org0mo
SWE Atlas: Neuer Benchmark für Coding Agents jenseits reiner Bug-Fixes
- BENCHMARKarxiv.org2d
EvoClaw: Benchmark enthüllt dramatischen Leistungsabfall von KI-Agenten bei Langzeit-Softwareentwicklung
- FORSCHUNGhuggingface.co2w
SpecBench misst Reward Hacking in Coding Agents anhand versteckter Test-Lücken
FrontierCode: Neues Benchmark misst ob Code wirklich merge-würdig ist
Warum es zählt
SWE-Bench-Scores täuschen über den echten Reifegrad von Coding-Agents hinweg. FrontierCode zeigt, dass mergefähiger Code ein deutlich schwiereres Ziel ist – relevant für Teams, die Agents produktiv in Codebases einsetzen wollen.
— Lumeric Redaktion
FrontierCode (hardest subset) · Spitzenwert
13%
Opus 4.8
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
- FORSCHUNGarxiv.org0mo
SWE Atlas: Neuer Benchmark für Coding Agents jenseits reiner Bug-Fixes
- BENCHMARKarxiv.org2d
EvoClaw: Benchmark enthüllt dramatischen Leistungsabfall von KI-Agenten bei Langzeit-Softwareentwicklung
- FORSCHUNGhuggingface.co2w
SpecBench misst Reward Hacking in Coding Agents anhand versteckter Test-Lücken