Lambert: Open-Source-Modelle fehlt der Agenten-Durchbruch wie Opus 4.5
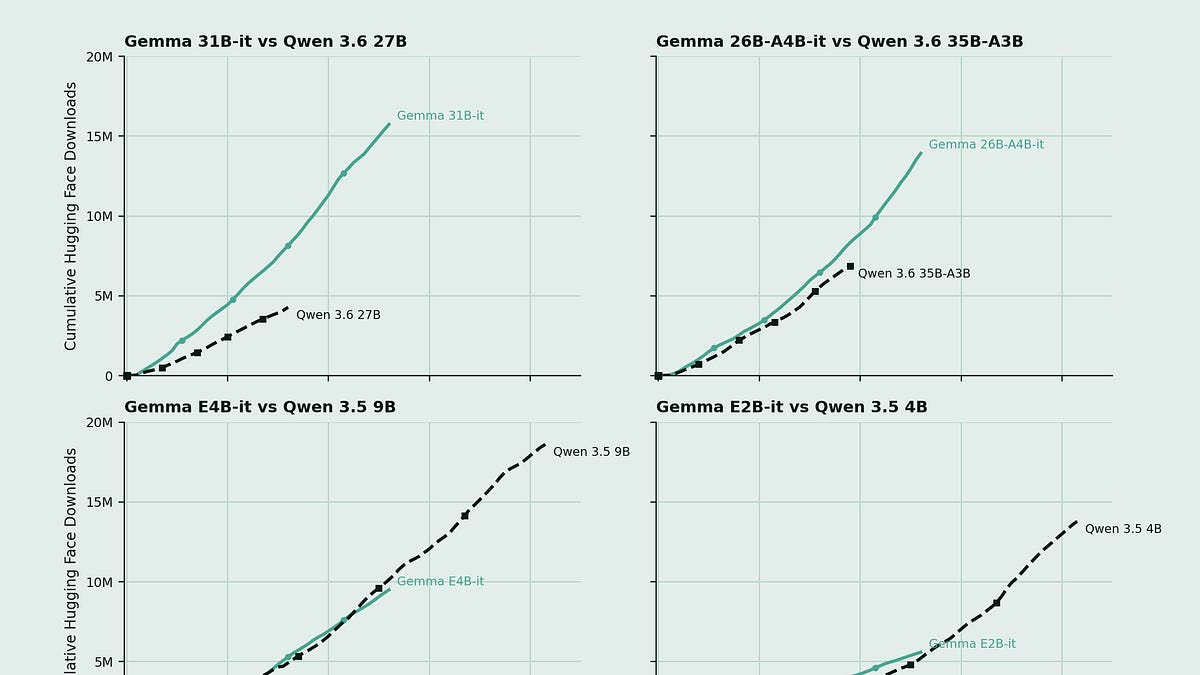
Nathan Lambert (Interconnects) skizziert in seinem Mai-2026-Rundblick fünf prägende Thesen zur KI-Entwicklung. Erstens: Open-Weight-Modelle haben noch keinen vergleichbaren Agenten-Durchbruch erlebt wie Claude Opus 4.5 mit Claude Code im Dezember 2025 — Lambert schätzt, der Rückstand könnte noch 12 oder mehr Monate andauern. Zweitens: Auch Google fehlt mit Gemini 3.5 Flash ein echter Konkurrent für Claude Code und Codex, was die Lücke zu Open-Source-Labs unterstreicht. Drittens: Ein open-weights Äquivalent zu Mythos — OpenAIs Modell, das Lambert als Meilenstein für Software-Engineering und Cybersecurity bezeichnet — erwartet er in diesem Jahr nicht; chinesische Labs seien ressourcenlimitiert, während amerikanische Top-Labs laut Epoch AI den Löwenanteil der Trainings-Compute-Kapazität kontrollieren (Google ~25 %, Meta ~11 %, OpenAI ~11 %, Anthropic ~6 %). Viertens: Amerikanische Open-Source-Modelle gewinnen an Fahrt — Gemma 4 mit Apache-2.0-Lizenz übertrifft Qwen 3.5/3.6 bei vergleichbarer Größe und verdrängt die chinesischen Modelle als Researcher-Standard. Modelle wie GPT-OSS, Nemotron 3 und Gemma 4 zeigen, dass ein permissives US-Modell in Benchmark-Reichweite schnell breite Adoption findet.
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
- MEINUNGinterconnects.ai2w
GLM-5.2 gilt als erster Open-Weight-Agent auf Niveau proprietärer Coding-Modelle
- MEINUNGreddit.com3w
Open-Weight-Modelle holen bei Kosten-Leistung gegenüber Closed APIs auf
- MEINUNGtechcrunch.com2w
US-Regierung blockiert GPT-5.6 und Anthropic-Modelle – Industrie unter Druck
- MEINUNGreddit.com3w
Community diskutiert: Wann kommen Open-Weight-Modelle auf Fable-5-Niveau?
Lambert: Open-Source-Modelle fehlt der Agenten-Durchbruch wie Opus 4.5
Nathan Lambert (Interconnects) skizziert in seinem Mai-2026-Rundblick fünf prägende Thesen zur KI-Entwicklung. Erstens: Open-Weight-Modelle haben noch keinen vergleichbaren Agenten-Durchbruch erlebt wie Claude Opus 4.5 mit Claude Code im Dezember 2025 — Lambert schätzt, der Rückstand könnte noch 12 oder mehr Monate andauern. Zweitens: Auch Google fehlt mit Gemini 3.5 Flash ein echter Konkurrent für Claude Code und Codex, was die Lücke zu Open-Source-Labs unterstreicht. Drittens: Ein open-weights Äquivalent zu Mythos — OpenAIs Modell, das Lambert als Meilenstein für Software-Engineering und Cybersecurity bezeichnet — erwartet er in diesem Jahr nicht; chinesische Labs seien ressourcenlimitiert, während amerikanische Top-Labs laut Epoch AI den Löwenanteil der Trainings-Compute-Kapazität kontrollieren (Google ~25 %, Meta ~11 %, OpenAI ~11 %, Anthropic ~6 %). Viertens: Amerikanische Open-Source-Modelle gewinnen an Fahrt — Gemma 4 mit Apache-2.0-Lizenz übertrifft Qwen 3.5/3.6 bei vergleichbarer Größe und verdrängt die chinesischen Modelle als Researcher-Standard. Modelle wie GPT-OSS, Nemotron 3 und Gemma 4 zeigen, dass ein permissives US-Modell in Benchmark-Reichweite schnell breite Adoption findet.
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
- MEINUNGinterconnects.ai2w
GLM-5.2 gilt als erster Open-Weight-Agent auf Niveau proprietärer Coding-Modelle
- MEINUNGreddit.com3w
Open-Weight-Modelle holen bei Kosten-Leistung gegenüber Closed APIs auf
- MEINUNGtechcrunch.com2w
US-Regierung blockiert GPT-5.6 und Anthropic-Modelle – Industrie unter Druck
- MEINUNGreddit.com3w
Community diskutiert: Wann kommen Open-Weight-Modelle auf Fable-5-Niveau?