State Space Models: Vom Nischenthema zum ernsthaften Transformer-Konkurrenten
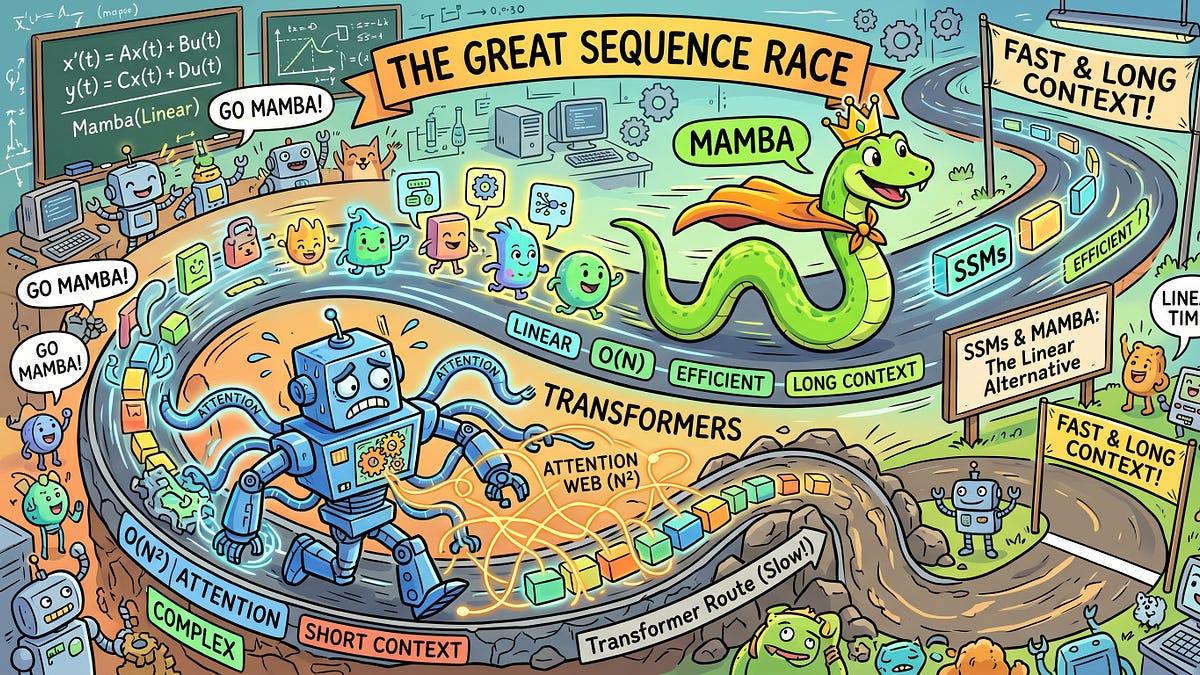
State Space Models (SSMs) haben sich laut diesem Beitrag aus TheSequence über rund acht Jahre schrittweise weiterentwickelt, während Transformer-Architekturen den Markt dominierten. Das zentrale Problem der Transformer — Self-Attention mit O(n²)-Komplexität in Bezug auf die Sequenzlänge — wird bei modernen Kontextfenstern jenseits einer Million Tokens zu einem handfesten Engineering-Engpass. Bei einem 70-Milliarden-Parameter-Modell kann allein der KV-Cache 40 GB VRAM belegen. SSMs bieten dagegen lineare Zeitkomplexität, konstanten Speicherbedarf zur Inferenzzeit und benötigen keinen KV-Cache. Der Artikel ordnet ein, dass SSMs seit etwa drei Jahren darauf gemessen werden, ob sie Transformer bei Sprachmodellierung, In-Context-Learning und Reasoning einholen können — und kommt zu dem Schluss, dass dies Stand März 2026 zunehmend der Fall ist. Der Volltext der mathematischen Grundlagen ist jedoch nur für zahlende Abonnenten zugänglich.
- Self-Attention skaliert quadratisch (O(n²)) mit der Sequenzlänge — bei >1 Mio. Tokens ein realer Flaschenhals
- KV-Cache eines 70B-Modells kann allein 40 GB VRAM beanspruchen
- SSMs bieten lineare Zeitkomplexität und konstanten Speicher zur Inferenzzeit ohne KV-Cache
- Laut Autor konkurrieren SSMs Stand März 2026 zunehmend mit Transformern bei Perplexity, In-Context-Learning und Reasoning
- Der Transformer dominiert seit ca. acht Jahren als einzige relevante Architektur im ML-Bereich
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.
Verwandte Beiträge
State Space Models: Vom Nischenthema zum ernsthaften Transformer-Konkurrenten
State Space Models (SSMs) haben sich laut diesem Beitrag aus TheSequence über rund acht Jahre schrittweise weiterentwickelt, während Transformer-Architekturen den Markt dominierten. Das zentrale Problem der Transformer — Self-Attention mit O(n²)-Komplexität in Bezug auf die Sequenzlänge — wird bei modernen Kontextfenstern jenseits einer Million Tokens zu einem handfesten Engineering-Engpass. Bei einem 70-Milliarden-Parameter-Modell kann allein der KV-Cache 40 GB VRAM belegen. SSMs bieten dagegen lineare Zeitkomplexität, konstanten Speicherbedarf zur Inferenzzeit und benötigen keinen KV-Cache. Der Artikel ordnet ein, dass SSMs seit etwa drei Jahren darauf gemessen werden, ob sie Transformer bei Sprachmodellierung, In-Context-Learning und Reasoning einholen können — und kommt zu dem Schluss, dass dies Stand März 2026 zunehmend der Fall ist. Der Volltext der mathematischen Grundlagen ist jedoch nur für zahlende Abonnenten zugänglich.
- Self-Attention skaliert quadratisch (O(n²)) mit der Sequenzlänge — bei >1 Mio. Tokens ein realer Flaschenhals
- KV-Cache eines 70B-Modells kann allein 40 GB VRAM beanspruchen
- SSMs bieten lineare Zeitkomplexität und konstanten Speicher zur Inferenzzeit ohne KV-Cache
- Laut Autor konkurrieren SSMs Stand März 2026 zunehmend mit Transformern bei Perplexity, In-Context-Learning und Reasoning
- Der Transformer dominiert seit ca. acht Jahren als einzige relevante Architektur im ML-Bereich
Frag die KI zum Artikel
Folgefragen zu Headline, Quelle und Volltext — Antwort streamt in wenigen Sekunden.