Samstag4. Juli
Anthropics Ambitionen (Claude Science, China-Bann) und die Neuvermessung von KI-Leistung (Benchmarks, Confidence-Theater) dominieren heute — dazu konkrete Bausteine für Infra-Builder von lokalem LLM-Betrieb bis Agenten-Architektur.


Anthropic steht dieser Woche im Mittelpunkt gleich mehrerer Entwicklungslinien — und keine davon ist trivial. Mit Claude Science, einem neuen „AI Workbench for Scientists", bündelt das Unternehmen fragmentierte wissenschaftliche Tools und Datensätze in einer Umgebung und richtet sich gezielt an Biotech- und Pharmakunden. Noch weitreichender ist die Ankündigung, selbst Medikamente entwickeln zu wollen: Head of Life Sciences Eric Kauderer-Abrams nannte „vernachlässigte" Krankheiten als Fokus, konkretere Details blieb Anthropic schuldig. Das schafft die ungewöhnliche Konstellation, dass ein KI-Anbieter gleichzeitig Software an Pharmaunternehmen verkauft und mit ihnen im Forschungsfeld konkurriert. Experten wie der Cambridge-Professor Namshik Han und Matthew Todd vom University College London weisen darauf hin, dass „AI Drug Discovery" ein Sammelbegriff für ein breites Spektrum von Anwendungen ist — von der Wirkstoffsuche bis zur Datenanalyse in klinischen Studien.

Doch Anthropics globale Ambitionen stoßen an geopolitische Grenzen. Alibaba soll laut einem internen Informanten planen, Claude Code am Arbeitsplatz zu verbieten — aus Sicherheitsbedenken wegen angeblicher Backdoor-Risiken. Der Vorgang ist symptomatisch für eine sich beschleunigende Fragmentierung des globalen KI-Tool-Ökosystems, bei der chinesische Tech-Konzerne westliche Entwicklungstools zunehmend aus ihren internen Stacks verdrängen. Gleichzeitig zeigt der explosionsartige Anstieg gemeldeter Sicherheitslücken eine andere Seite KI-gestützter Werkzeuge: Laut Epoch AI wurden im Juni 2026 rund 1.500 hochkritische CVEs gemeldet — mehr als das 3,5-Fache des bisherigen Monatsrekords. Der Zeitpunkt korreliert mit Anthropics April-Ankündigung, dass Claude Mythos Preview eigenständig Software-Schwachstellen aufspüren kann; Anthropics „Glasswing"-Programm soll bereits über 10.000 hoch- oder kritische Schwachstellen identifiziert haben. Security-Teams stehen damit vor einem dauerhaft erhöhten Patch- und Triage-Aufwand.
Hinter diesen Produktnachrichten liegt ein tieferes methodisches Problem: Wie misst man, was KI-Systeme wirklich können? Das UK AI Security Institute (AISI) hat sieben Frontier-Benchmarks mit variierenden Compute-Budgets getestet und kommt zu einem klaren Befund: Feste Token-Obergrenzen unterschätzen die tatsächliche Leistungsfähigkeit von KI-Agenten systematisch. Bei Cybersecurity-Tasks ließen sich rund 8 Prozent der Aufgaben erst ab einem Budget von mehr als 10 Millionen Tokens lösen, manche erst ab 50 Millionen. Bei Software-Engineering-Benchmarks wie SWE-Bench Pro stiegen die Erfolgsquoten um bis zu 25 Prozent, wenn das Token-Budget von einer auf zehn Millionen wuchs. Besonders aufschlussreich: Neuere Modelle profitieren überproportional von größeren Budgets. Die AISI-Forscher zeigen zudem, dass der Token-Bedarf eines Agenten einem Potenzgesetz folgt — je länger ein menschlicher Experte für eine Aufgabe braucht, desto mehr Tokens benötigt das Modell. Dieser Befund muss auch im Kontext von KI-Confidence-Theater gelesen werden: Die Autorin Elena Verna beschreibt, wie aufgeblasene KI-Versprechen echte Nutzererfahrungen vergiften — wer ein System als „lebensverändernd" ankündigt, das nur 50 Prozent der Zeit korrekt funktioniert, untergräbt das Vertrauen in das gesamte Feld.
Für Infrastruktur-Builder liefert der heutige Tag konkrete Bausteine. Ein Hobbyist demonstriert mit einem selbstgebauten 12-GPU-Cluster mit 448 GB VRAM, dass Consumer- und Prosumer-GPUs — eine Mischung aus RTX Pro 6000, 3090 und 5090 — via Pipeline-Parallelismus ausreichen, um MiniMax M3 in AWQ-INT4 mit rund 30 Tokens/s (Single-Stream) und ~960 Tokens/s (Batch) zu betreiben. Auf der Sampling-Ebene ergänzt ein experimenteller „Scatter"-Sampler für llama.cpp das lokale Toolkit: Er glättet die Next-Token-Wahrscheinlichkeitsverteilung via Gauß-Kernel über Token-Ränge, ohne Wahrscheinlichkeit in den Tail zu verschieben — ein noop-kompatibler Baustein für weichere Generierung ohne die Nebenwirkungen hoher Temperatur.

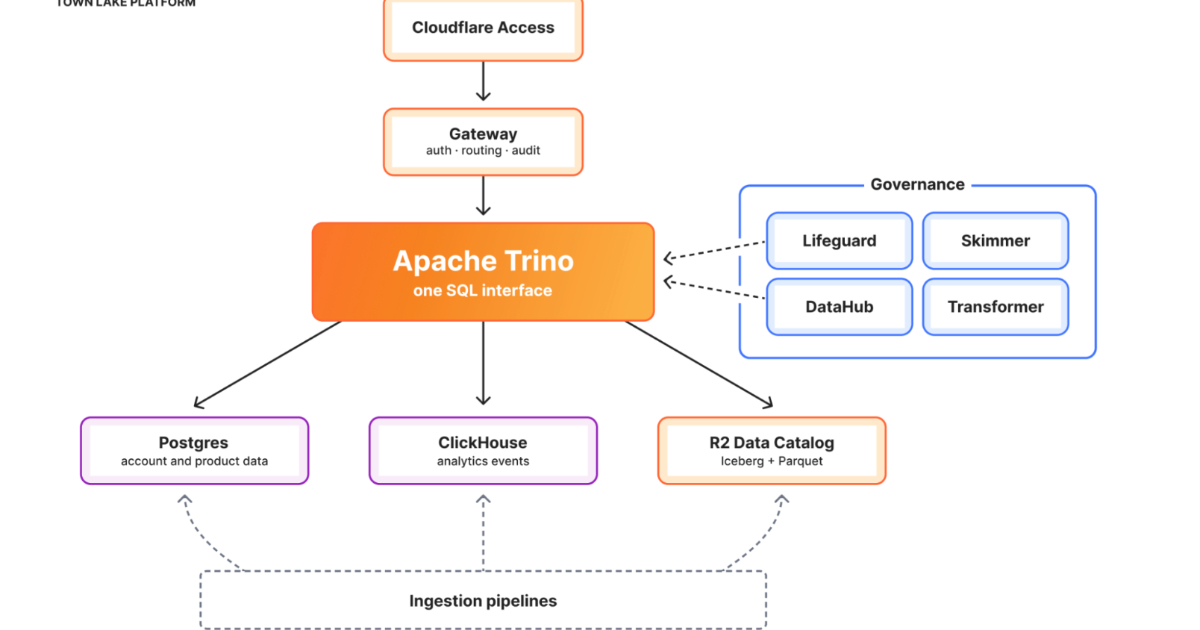
Auf Architekturebene bieten zwei Referenzpunkte Orientierung. Cloudflares Town Lake und der KI-Analyseagent Skipper zeigen, wie ein Infrastrukturunternehmen heterogene Datenquellen — Postgres, ClickHouse, Kafka, BigQuery und Objektspeicher — unter einer gouvernierten Lakehouse-Plattform zusammenführt und per natürlichsprachlichem Agent zugänglich macht; Billing-Workloads machen 53 Prozent aller Plattform-Queries aus. Wer Agenten-Logik von Grund auf verstehen will, findet in der Erklärung des ReAct-Loops das konzeptuelle Fundament: Reason, Act, Observe — drei Schritte, die sich wiederholen, bis das Modell genug Kontext hat, um zu antworten, und die genau dort einspringen, wo paralleles Tool Calling an seine Grenzen stößt. Den Blick auf das größere Ökosystem bietet schließlich die Open Source AI Gap Map von Current AI: 421 Produkte in 14 Kategorien, MIT-lizenzierte YAML-Rohdaten auf GitHub und 16.185 getrackte Repos als Datasette-Lite-Ansicht — ein systematischer Einstiegspunkt für alle, die Lücken im Open-Source-KI-Stack kartieren wollen.
Frag das Briefing
Pro


- Fr., 3. JuliAgenten-Tooling reift: Von MCP-Servern über Coding-Agents bis zur Multi-Modell-Orchestrierung verdichten sich heute konkrete Builder-Signale. Daneben setzen Anthropics Fable-5-Updates und Zuckerbergs Ernüchterung den Rahmen, wie weit Frontier-KI wirklich ist.10
- Do., 2. JuliAgenteninfrastruktur und Inferenz-Optimierung dominieren heute: AWS baut End-to-End-Cloud-Stack für Agenten, während Anthropic mit einem Vertrauensschaden auffällt. Dazu: Cloudflares Crawler-Ultimatum zwingt AI-Firmen zur Neu-Architektur ihrer Web-Zugriffe.10
- Mi., 1. JuliClaude Sonnet 5 und die Agentic-Welle dominieren den Tag: Anthropic setzt neue Kostenmaßstäbe für autonome Workflows, während Sicherheitslücken in KI-Browsern und versteckte Steganographie in Claude Code zeigen, dass die Agent-Ära auch neue Angriffsflächen mitbringt.10
- Di., 30. JuniAgentic AI dominiert heute auf zwei Achsen: Skalierung (Memora, ENPIRE, Gartner-Outlook) und Sicherheit (Claude-Code-Malware, Meta-Datenprovenienz). Daneben setzen konkrete Tool-Releases und Markt-Infrastruktur-Moves den Builder-Takt.10
